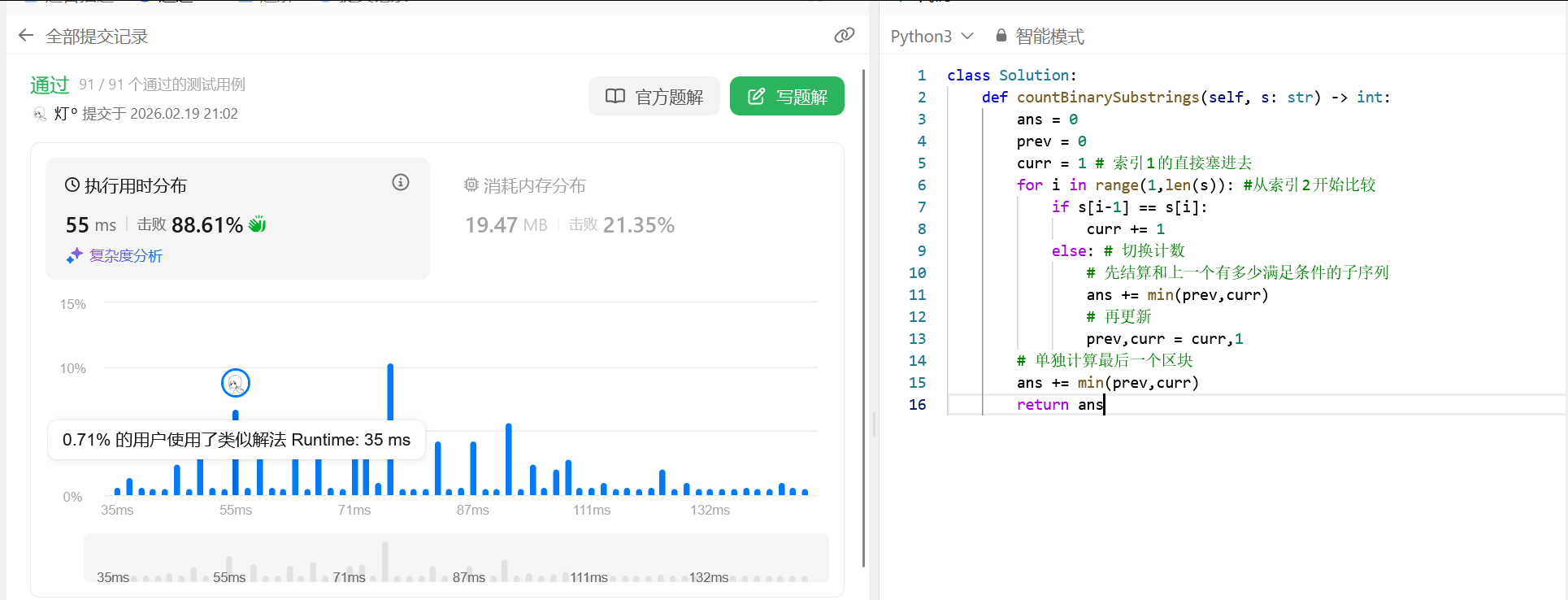
696. 计数二进制子串
696 计数二进制子串
题目链接:696. 计数二进制子串
错误暴力解
尝试遍历所有子串,排除长度不是偶数的子串后对半分开检查是否全是 1 和 0。
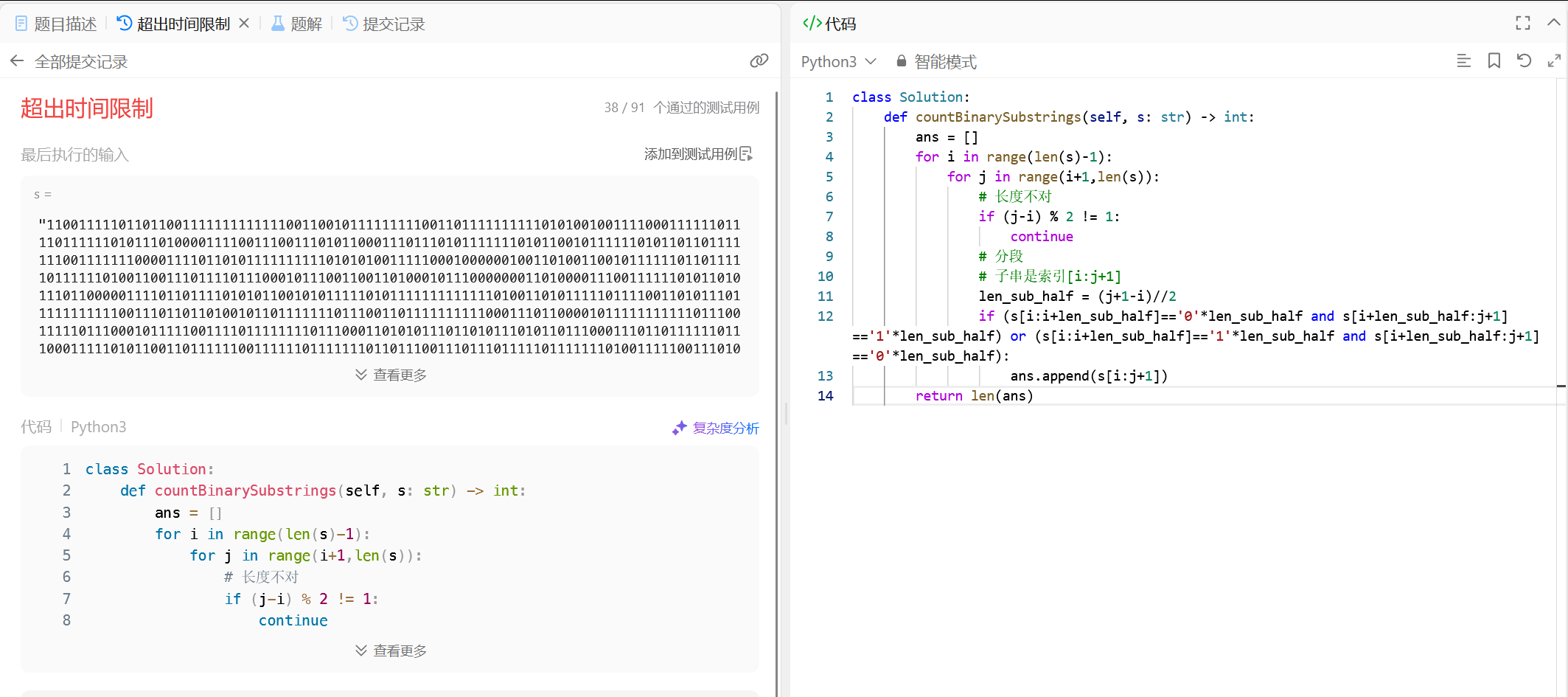
这种情况会导致 Time Limit Exceeded (TLE),因为对于长字符串,$O(n^2)$ 或 $O(n^3)$ 的复杂度所需时间太长。
正解:从“框选”到“压缩”
在处理海量序列数据时,核心思维是状态压缩与流式处理。我们不需要去暴力框选每一个子串,而是去看数据的“区块特征”。
拿输入 "00110011" 来说,不要把它当成独立的 8 个字符,把它压缩成连续相同字符的“区块长度”:
- 有 2 个 ‘0’
- 有 2 个 ‘1’
- 有 2 个 ‘0’
- 有 2 个 ‘1’
压缩后的特征数组就是:[2, 2, 2, 2]。
破局的核心逻辑在于:
任何相邻的两个区块(比如 $m$ 个 ‘0’ 紧挨着 $n$ 个 ‘1’),它们能组成多少个符合题意的有效子串?
答案就是它们的最小值:$\min(m, n)$。
比如一段日志 000011(特征为 [4, 2]),因为 ‘1’ 只有两个,所以最多只能和相邻的两个 ‘0’ 凑成 0011 和 01,总共 $\min(4, 2) = 2$ 个。
优化空间复杂度
既然我们只需要比较相邻区块的长度,我们甚至都不需要把完整的 [2, 2, 2, 2] 数组存下来(省去 $O(n)$ 的空间)。我们只需要维护两个变量:上一个区块的长度 (prev_len) 和 当前区块的长度 (curr_len)。
这非常像在处理数据流(Data Stream)的状态机逻辑:
1 | class Solution: |
复杂度分析
- 时间复杂度:$O(n)$,只需遍历一次字符串。
- 空间复杂度:$O(1)$,只使用了常数个变量。