438. 找到字符串中所有字母异位词
438 找到字符串中所有字母异位词
题目链接:438. 找到字符串中所有字母异位词
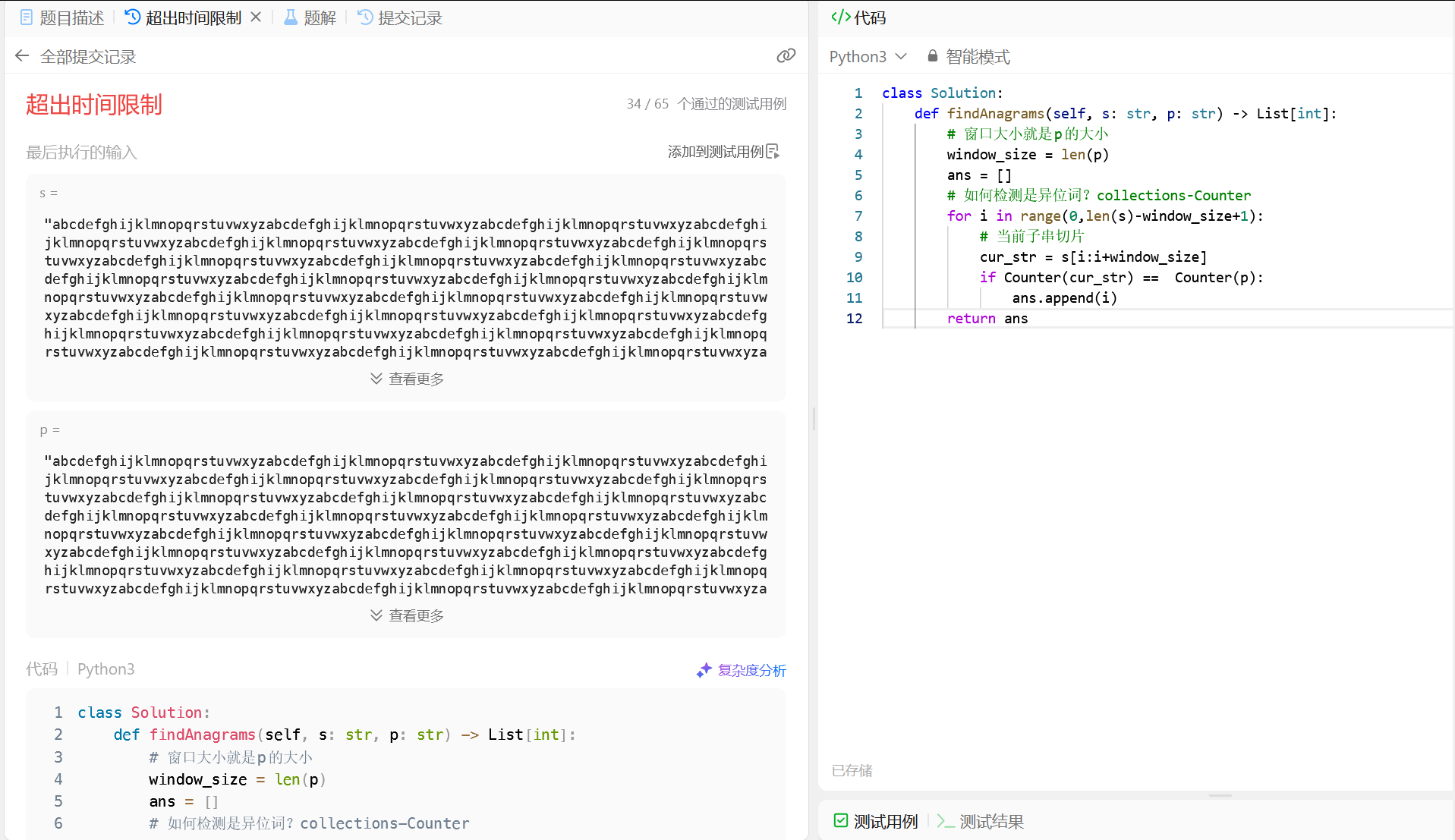
暴力遍历 (超时解)
最直白的想法是,遍历原字符串 s,每次截取和 p 长度相等的子串,然后比较两者的字符构图是否一致。
为了比较字符的出现次数,我们使用了 Python 内置的 collections.Counter 计数器组件:
1 | from collections import Counter |
复杂度分析
该方法在长字符串用例下会触发超时 (TLE),原因在于其时间复杂度过高。
设字符串 s 的长度为 $N$,目标字符串 p 的长度为 $K$。
时间复杂度:$O(N \times K)$
外层循环遍历s,时间复杂度为 $O(N)$。在循环内部,进行字符串切片s[i:i+k]及Counter字典构建,这些操作都需要遍历长度为 $K$ 的子串,时间复杂度均为 $O(K)$。
两相嵌套使得整体时间复杂度退化为 $O(N \times K)$。在极端情况下,$N, K \sim 3 \times 10^4$,计算量会达到 $10^9$ 级别,这必然导致超时。空间复杂度:$O(K)$ 或 $O(|\Sigma|)$
Counter生成的哈希表最多包含小写英文字母范围内的状态($|\Sigma|=26$),因此这部分的常数空间为 $O(1)$。但由于隐式的字符串切片操作,底层的内存分配需额外的 $O(K)$ 空间。
优化思路:需消除每次循环中重复的 $O(K)$ 级切片和计数操作。
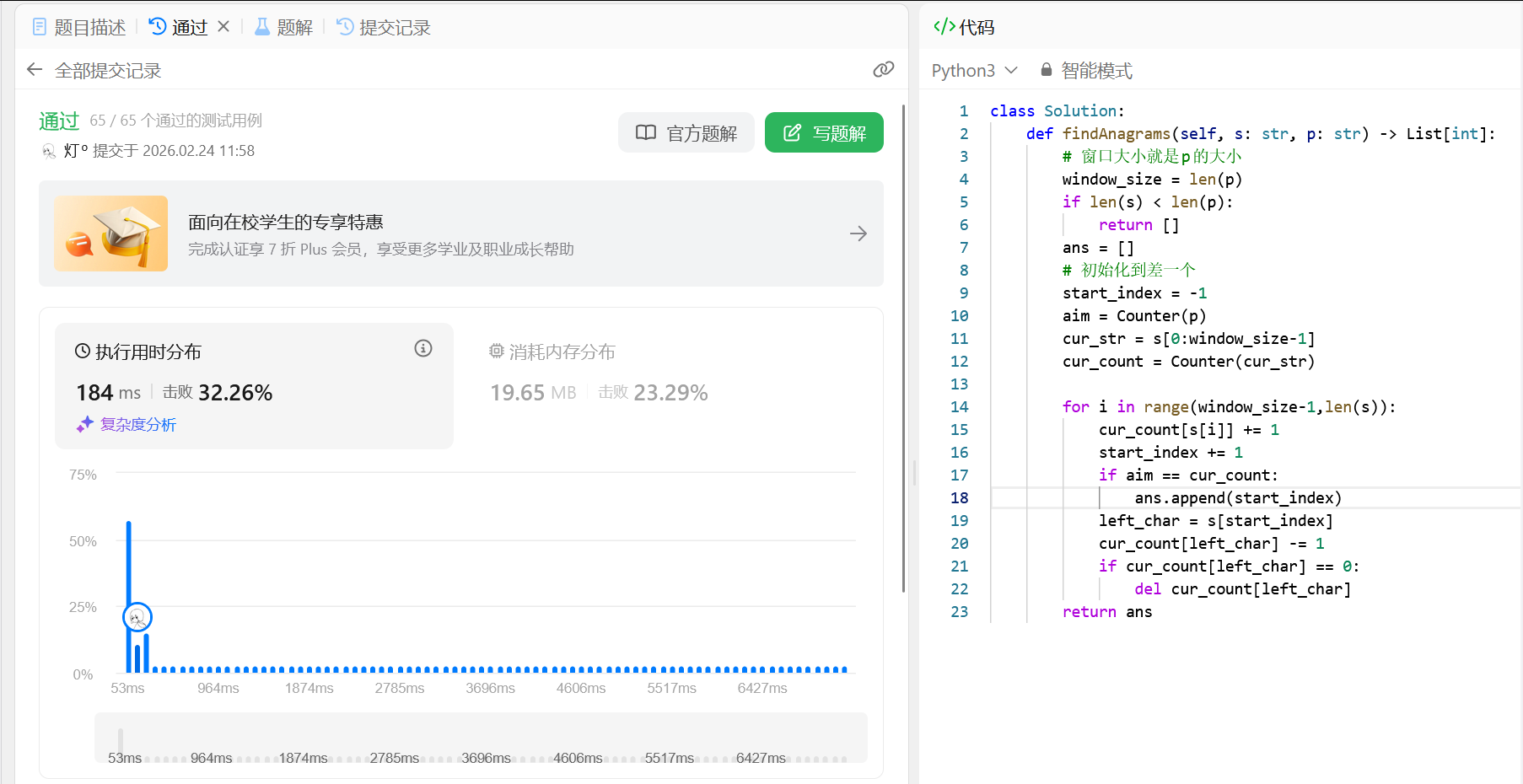
优化解:定长滑动窗口 (Fixed Sliding Window)
为了消除每次循环中重复的 $O(K)$ 级切片和计数操作,我们可以引入定长滑动窗口。
其核心思路是:窗口的大小始终固定为字符串 p 的长度 $K$。当窗口在字符串 s 上整体向右滑行时,除了移出窗口的最左侧字符和进入窗口的最右侧字符,中间绝大多数的字符状态都不会改变。因此,我们只需要“进局一个、出局一个”,通过动态维护原本的字典计数,就能实现增量更新。
1 | from collections import Counter |
复杂度分析
时间复杂度:$O(N)$
初始化第一个窗口占用 $O(K)$(Counter(cur_str)),外层循环滑动窗口遍历剩余的 $N-K$ 个字符,占用 $O(N-K)$。
每次循环中,字典的增减操作(进一个、出一个)都是极其高效的 $O(1)$。
对比字典aim == cur_count操作耗时视作 $O(|\Sigma|) = O(1)$(26个字母常数级)。
因此总时间复杂度从 $O(N \times K)$ 蜕变降维缩减为 $O(N)$,轻松通过长字符校验。空间复杂度:$O(|\Sigma|) \sim O(1)$
aim和cur_count这两个哈希表只记录小写英文字母的分布情况,最多占据 $O(26)$ 个大小的状态空间,不受输入字符串实际规模大小的限制。因此为常数级空间复杂度。
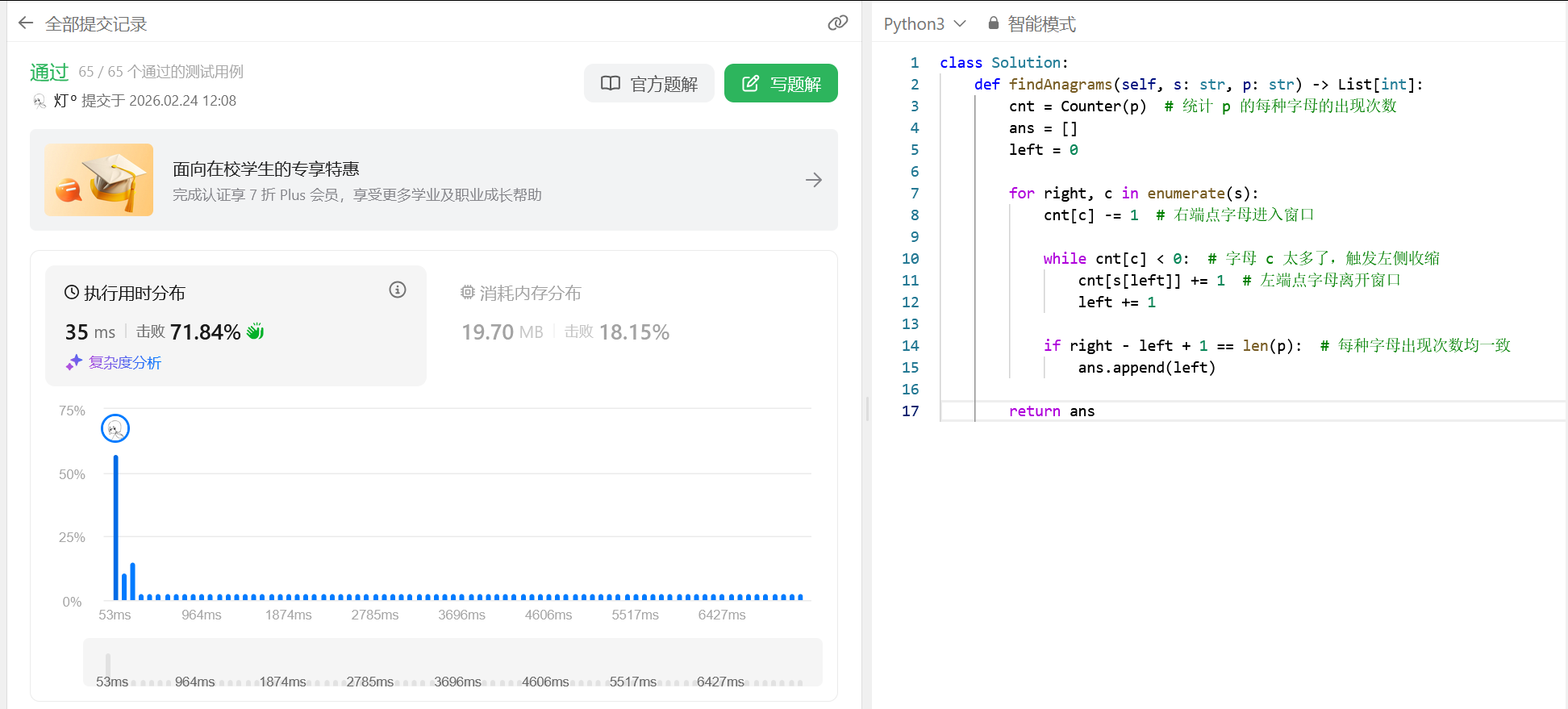
优化解:不定长滑动窗口 (Variable Sliding Window)
除了保证窗口固定长度外,另外一种主流的写法是不定长滑动窗口。这种由于不强制初始维持 $K-1$ 个字符,代码结构更加精简。
其核心在于动态维护一个“合法的窗口”:让右侧指针 right 向右扩展,将字符纳入窗口抵扣 cnt 计数。一旦发现加入后某个字符数量出现“超载”(即 cnt[c] < 0),便持续收缩左指针 left,将字符移出窗口,直至不合规状态被消除。只要窗口处于合法状态且长度正好等于 p 的长度,即为一个有效的异位词起点。
1 | class Solution: |
最佳实践来源: 灵茶山艾府 - 两种方法:定长滑窗/不定长滑窗
复杂度分析
时间复杂度:$O(N)$
外层for循环推进右指针right,内层while循环推进左指针left。两个指针各自最多单调遍历字符串长度 $N$ 一次,因此均摊到每次循环内部的哈希操作均为常数时间。整体时间复杂度保持为 $O(N)$。空间复杂度:$O(|\Sigma|) \sim O(1)$
字典cnt仅记录字符集大小的状态,受限于英语字母表,占用 $O(26) = O(1)$ 常数空间。